Application IA RAG sur mesure : architecture, cas d'usage et méthode complète pour déployer une IA fiable en entreprise en 2026
Les entreprises cherchent aujourd'hui à exploiter leurs données internes avec l'intelligence artificielle sans compromettre la sécurité, la fiabilité ou la pertinence des réponses générées. Les modèles de langage comme GPT, Claude ou Llama ont démontré une puissance remarquable, mais ils restent limités lorsqu'ils doivent accéder à des informations spécifiques à une organisation. C'est précisément dans ce contexte que l'application IA RAG sur mesure s'impose comme une architecture stratégique. Le Retrieval Augmented Generation permet de connecter un modèle de langage à des sources de données internes, structurées ou non structurées, afin de produire des réponses contextualisées et vérifiables. En 2026, plus de 63 % des projets d'IA générative en entreprise intègrent une architecture RAG, selon plusieurs études sectorielles, car cette approche permet de réduire drastiquement les hallucinations et d'améliorer la précision des réponses. Une application RAG personnalisée ne consiste pas simplement à brancher un chatbot sur des documents, mais à concevoir une architecture complète combinant ingestion de données, recherche sémantique, base vectorielle et orchestration du contexte. Une compréhension approfondie de cette architecture devient donc indispensable pour concevoir une solution IA réellement utile et durable.
Comprendre le fonctionnement d'une application IA RAG sur mesure
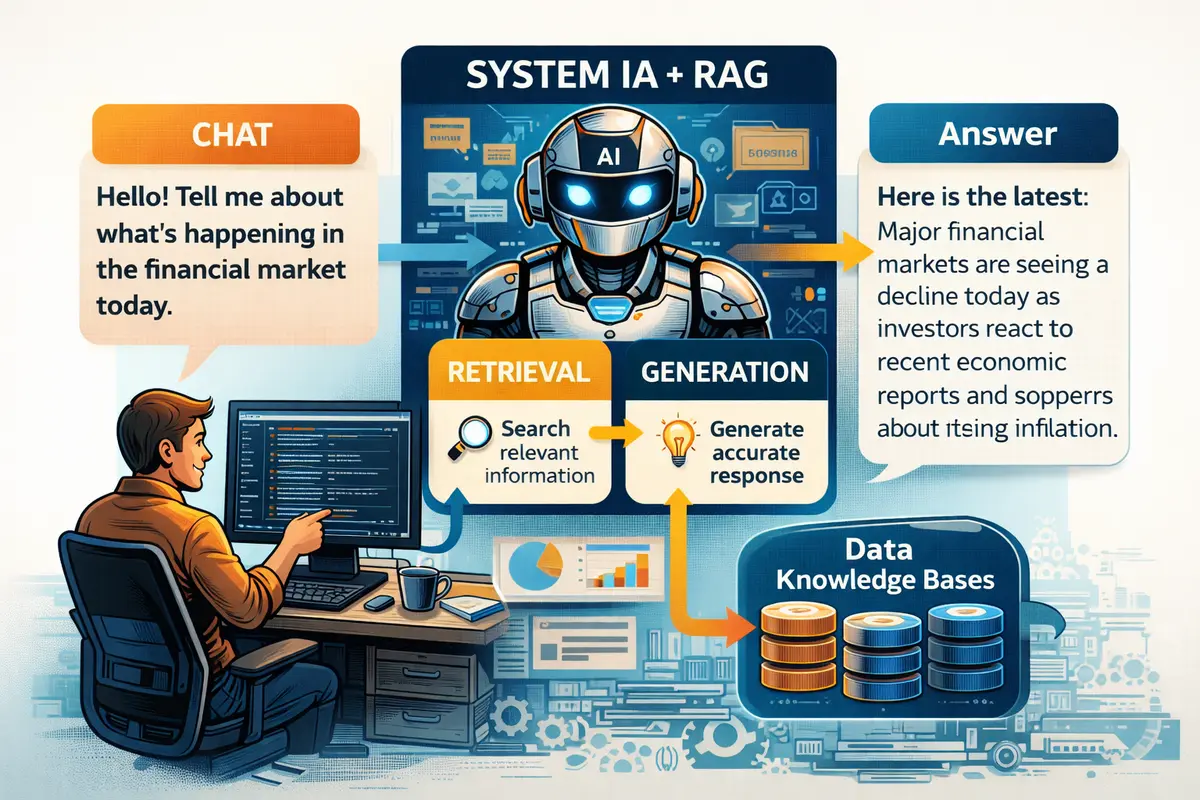
Une application IA RAG sur mesure combine un modèle de langage avec un système de récupération d'informations permettant d'injecter du contexte pertinent dans chaque requête utilisateur. Contrairement à un chatbot générique, l'architecture RAG ne repose pas uniquement sur les connaissances pré-entraînées du modèle mais sur une base documentaire dynamique et actualisée. Le principe consiste à rechercher les informations pertinentes dans une base de connaissances interne avant de générer la réponse finale. Cette approche améliore considérablement la précision des réponses tout en permettant de travailler sur des données sensibles ou spécifiques à une organisation. En 2026, cette architecture devient un standard dans les projets d'IA d'entreprise car elle combine puissance de génération linguistique et contrôle sur les sources utilisées.
Le principe du Retrieval Augmented Generation
Le Retrieval Augmented Generation repose sur un processus en deux phases distinctes : la récupération d'informations pertinentes puis la génération d'une réponse contextualisée. Lorsqu'un utilisateur pose une question, le système identifie d'abord les documents ou fragments de documents les plus proches sémantiquement de la requête. Ces extraits sont ensuite injectés dans le prompt envoyé au modèle de langage, qui produit une réponse basée sur ces informations. Ce mécanisme réduit fortement les réponses inventées par les modèles et améliore la traçabilité des sources. Dans un contexte professionnel, cela permet par exemple d'interroger une base documentaire interne, un référentiel technique ou une base de connaissances client.
Pourquoi le RAG sur mesure est devenu indispensable en 2026
Les entreprises produisent aujourd'hui des volumes massifs de données dispersées dans différents systèmes : bases documentaires, intranets, CRM, ERP ou bases de support client. Un modèle de langage seul ne peut pas accéder à ces informations ni les comprendre correctement sans architecture adaptée. Une application RAG sur mesure permet d'unifier ces sources et d'exploiter la connaissance interne de l'entreprise de manière conversationnelle. Selon plusieurs rapports publiés en 2026, les organisations qui utilisent un système RAG constatent une amélioration moyenne de 40 % de la pertinence des réponses comparé à un chatbot classique. Cette approche transforme donc l'IA générative en véritable outil opérationnel plutôt qu'en simple interface conversationnelle.
Les composants techniques d'une architecture RAG
Une architecture RAG repose sur plusieurs briques technologiques qui fonctionnent ensemble pour transformer des données brutes en réponses intelligentes. La performance globale du système dépend de la qualité de chacune de ces briques, depuis la préparation des données jusqu'au modèle de génération. Une application RAG sur mesure doit donc être pensée comme un système complet et non comme une simple intégration de chatbot. L'architecture inclut généralement des mécanismes d'ingestion documentaire, des embeddings vectoriels, un moteur de recherche sémantique et un orchestrateur capable de structurer le contexte envoyé au modèle de langage. La maîtrise de ces composants constitue la clé d'un système performant et évolutif.
Ingestion et préparation des données
La première étape d'un projet RAG consiste à collecter et préparer les données qui serviront de base de connaissance au système. Les sources peuvent inclure des documents PDF, des bases de données, des pages web internes ou des historiques de conversations clients. Une phase de nettoyage est ensuite nécessaire afin d'éliminer les contenus obsolètes, les doublons ou les informations incohérentes. Cette étape garantit que le système travaille uniquement sur des données fiables et pertinentes. Une préparation documentaire rigoureuse améliore fortement la précision des résultats générés par le système.
Le rôle du chunking et des métadonnées
Les documents doivent ensuite être découpés en segments appelés chunks afin de permettre une recherche sémantique efficace. Un document complet est souvent trop volumineux pour être injecté dans un modèle de langage, il est donc fragmenté en unités plus petites contenant chacune une idée cohérente. Chaque segment peut être enrichi de métadonnées comme le titre, l'auteur ou la date de publication afin d'améliorer la pertinence des recherches. Cette structuration facilite également le filtrage des informations selon des critères spécifiques. Une stratégie de chunking bien conçue constitue l'un des facteurs les plus déterminants dans la qualité d'un système RAG.
Embeddings et recherche vectorielle
Après la segmentation des documents, chaque fragment est transformé en vecteur numérique appelé embedding. Ces vecteurs représentent la signification sémantique du texte et permettent de comparer rapidement la proximité entre différentes informations. Les embeddings sont stockés dans une base vectorielle spécialisée capable d'effectuer des recherches rapides sur des millions de données. Lorsqu'un utilisateur pose une question, la requête est elle-même convertie en vecteur et comparée aux vecteurs existants pour identifier les contenus les plus pertinents. Cette technique permet de trouver des informations même lorsque la formulation de la question diffère du texte original.
Génération de réponse avec un modèle de langage
Une fois les documents pertinents identifiés, le système construit un prompt enrichi contenant ces extraits ainsi que la question de l'utilisateur. Ce prompt est ensuite envoyé au modèle de langage chargé de générer la réponse finale. Le modèle s'appuie sur les informations fournies pour produire une réponse cohérente et contextualisée. Cette approche limite les hallucinations et améliore la fiabilité des réponses. Elle permet également de citer les sources utilisées, ce qui renforce la confiance des utilisateurs.
Les cas d'usage les plus pertinents d'une application RAG
Le potentiel d'une application IA RAG sur mesure dépend largement du contexte métier dans lequel elle est déployée. Certaines fonctions de l'entreprise bénéficient particulièrement de cette technologie car elles reposent sur des volumes importants de connaissances documentaires. Le RAG transforme alors l'accès à l'information en une interaction conversationnelle rapide et contextualisée. Cette approche améliore la productivité des équipes et réduit le temps consacré à la recherche d'informations. Les organisations qui déploient ces systèmes constatent souvent un gain significatif dans la circulation interne de la connaissance.
Support client et base de connaissances
Les équipes de support client doivent souvent répondre à des questions complexes nécessitant l'accès à de nombreuses sources documentaires. Une application RAG peut analyser la base de connaissances interne, les procédures techniques ou les historiques de tickets afin de proposer des réponses pertinentes. Les agents peuvent ainsi obtenir des informations fiables en quelques secondes sans parcourir manuellement plusieurs systèmes. Cette assistance réduit le temps moyen de résolution des incidents et améliore la satisfaction client. Dans certains cas, l'IA peut également répondre directement aux demandes simples des utilisateurs.
Recherche documentaire interne
Dans les grandes organisations, la recherche d'informations constitue un défi majeur car les documents sont répartis dans de multiples systèmes. Une application RAG permet de centraliser virtuellement ces contenus et de les rendre accessibles via une interface conversationnelle. Les collaborateurs peuvent poser des questions complexes et obtenir des réponses synthétiques basées sur plusieurs documents. Cette approche réduit la fragmentation de la connaissance et améliore la collaboration entre équipes. Elle transforme également la documentation interne en véritable actif stratégique.
Analyse réglementaire et juridique
Les secteurs fortement réglementés comme la finance, l'assurance ou la santé doivent traiter des volumes considérables de textes juridiques. Un système RAG peut analyser ces documents et fournir des réponses contextualisées sur des obligations réglementaires spécifiques. Les juristes peuvent ainsi interroger directement les textes de loi ou les procédures internes. Cette capacité accélère la recherche juridique tout en améliorant la conformité des décisions prises. L'IA devient alors un outil d'aide à la décision particulièrement puissant.
Architecture d'une application RAG en production
Concevoir une application RAG en environnement réel implique de dépasser largement le simple prototype technique. Une architecture robuste doit gérer la sécurité, la scalabilité, l'actualisation des données et la supervision des performances. Les organisations doivent également choisir entre différentes approches technologiques comme les solutions cloud, les architectures hybrides ou les déploiements on-premise. Chaque choix influence les coûts, la sécurité et la flexibilité du système. Une architecture bien conçue garantit la pérennité de l'application sur plusieurs années.
Les principales briques d'une architecture RAG
Une architecture RAG complète inclut généralement plusieurs composants spécialisés qui interagissent entre eux pour produire les réponses finales. Chaque composant joue un rôle spécifique dans la chaîne de traitement de l'information et contribue à la performance globale du système. La conception de cette architecture doit tenir compte des contraintes techniques et des besoins métiers. Les organisations qui maîtrisent ces briques technologiques peuvent construire des systèmes IA puissants et évolutifs.
- Collecte et ingestion de données
- Nettoyage et structuration documentaire
- Génération d'embeddings
- Base de données vectorielle
- Moteur de recherche sémantique
- Orchestrateur de prompts
- Modèle de langage génératif
- Interface utilisateur conversationnelle
Préparer ses données pour un système RAG performant
La performance d'une application RAG dépend avant tout de la qualité des données utilisées pour alimenter le système. Les organisations qui négligent cette étape constatent rapidement une dégradation de la pertinence des réponses générées par l'IA. Les données doivent être nettoyées, structurées et enrichies afin de faciliter la recherche sémantique. Une gouvernance documentaire solide devient donc un élément central du projet. La préparation des données constitue souvent la phase la plus longue d'un déploiement RAG.
Structuration et qualité documentaire
Une base documentaire bien structurée améliore considérablement la capacité du système à récupérer les bonnes informations. Les titres, sous-titres et résumés jouent un rôle crucial dans la compréhension du contenu par les algorithmes. L'ajout de métadonnées permet également de filtrer les résultats selon des critères spécifiques comme la date ou la source. Cette structuration facilite la maintenance du système et améliore l'expérience utilisateur. Les organisations doivent donc investir dans la qualité de leur documentation avant même de déployer l'IA.
Actualisation continue des données
Les données internes évoluent constamment et un système RAG doit refléter ces changements pour rester pertinent. Les pipelines d'ingestion automatisés permettent de mettre à jour la base vectorielle dès qu'un nouveau document est publié ou modifié. Cette actualisation garantit que les réponses générées reposent toujours sur les informations les plus récentes. Dans les environnements critiques, certaines organisations mettent à jour leur base documentaire plusieurs fois par jour. Cette dynamique renforce la fiabilité du système.
Combien coûte une application IA RAG sur mesure
Le coût d'un projet RAG varie fortement selon la complexité de l'architecture et le volume de données à traiter. Une application simple peut être développée avec quelques dizaines de milliers d'euros, tandis qu'un système d'entreprise peut dépasser plusieurs centaines de milliers d'euros. Les principaux facteurs de coût incluent l'infrastructure cloud, les appels aux modèles de langage et le stockage vectoriel. Les coûts d'intégration et de maintenance doivent également être pris en compte dans le calcul du retour sur investissement. Une analyse financière détaillée permet d'anticiper ces dépenses et d'optimiser l'architecture technique.
Les erreurs fréquentes dans les projets RAG
De nombreuses entreprises lancent des projets d'IA générative sans comprendre pleinement les contraintes d'une architecture RAG. Les erreurs les plus fréquentes concernent la qualité des données, la mauvaise structuration des documents ou l'absence de stratégie de gouvernance. Certains projets échouent également parce qu'ils tentent d'intégrer trop de sources de données dès le départ. Une approche progressive permet généralement d'obtenir de meilleurs résultats. La réussite d'un projet RAG dépend donc autant de la stratégie que de la technologie.
Mini FAQ sur les applications IA RAG sur mesure
Qu'est-ce qu'une application IA RAG sur mesure
Une application IA RAG sur mesure est un système qui combine un modèle de langage avec une base de connaissances interne afin de produire des réponses contextualisées. Contrairement à un chatbot classique, elle récupère des informations pertinentes dans des documents avant de générer la réponse finale. Cette architecture permet d'exploiter les données internes d'une organisation de manière conversationnelle. Elle améliore également la précision et la fiabilité des réponses. Les entreprises utilisent ce type de solution pour valoriser leur capital informationnel.
Quelle est la différence entre RAG et fine tuning
Le fine tuning consiste à réentraîner un modèle de langage sur un jeu de données spécifique afin de modifier son comportement. Le RAG fonctionne différemment car il n'altère pas le modèle lui-même mais lui fournit du contexte externe lors de chaque requête. Cette approche permet d'intégrer des données actualisées sans devoir réentraîner le modèle. Elle est également plus flexible et moins coûteuse dans de nombreux cas. Les entreprises privilégient donc souvent le RAG pour leurs applications internes.
Quand faut-il utiliser une architecture RAG
Une architecture RAG est particulièrement pertinente lorsque l'IA doit accéder à des informations spécifiques à une organisation. Elle est également utile lorsque les données évoluent régulièrement et doivent être mises à jour rapidement. Les secteurs qui disposent de grandes bases documentaires tirent un bénéfice important de cette approche. Les systèmes RAG sont donc très utilisés dans le support client, la gestion documentaire et l'analyse réglementaire. Ils transforment la connaissance interne en ressource accessible instantanément.